

José García Nieto
EditorLos Google Pixel son uno de los máximos exponentes en fotografía móvil. A pesar de seguir manteniendo una sola lente en la parte trasera, los dispositivos de la Gran G son capaces de obtener imágenes nocturnas de alta definición y mantener el detalle cuando hacemos zoom, todo ello gracias a la IA y los algoritmos, lo que solemos llamar "fotografía computacional".
Todo sucede en segundo plano y nada más pulsar el botón de disparo, pero detrás de cada toma hay una serie de procesos que ayudan a que el resultado final sea lo más perfecto posible. En esta ocasión, Google ha publicado el paper en el que explican cómo funciona el algoritmo encargado del zoom de alta resolución (que también se aplica en Night Sight). Lo detallaremos a continuación, pero se puede resumir en seis palabras: toma varias fotos y las combina.

Varias fotos en RAW combinadas para obtener el mejor resultado
Empezamos por lo básico. Como señalan desde Google, "comparadas con las cámaras DSLR, las cámaras de los smartphones tiene un sensor más pequeño, lo que limita su resolución; aperturas más bajas, lo que limita su capacidad de captación de luz; y píxeles más pequeños, lo que reduce su relación señal/ruido". Además, se tienen que usar matrices de filtros de color para hacer la interpolación cromática y reconstruir la imagen (proceso conocido como "demosaicing"), lo que reduce todavía más la resolución.
Lo que Google ha hecho ha sido sustituir esta interpolación cromática convencional por un algoritmo multi fotograma de alta resolución que se encarga de completar las imágenes en RGB mediante una ráfaga de imágenes RAW (entre siete y 15, según la luz) tomadas desde diferentes ángulos. ¿Pero cómo desde diferentes ángulos, si cuando echamos una foto estamos quietos? Fácil, usando el temblor que se produce al disparar a mano alzada.
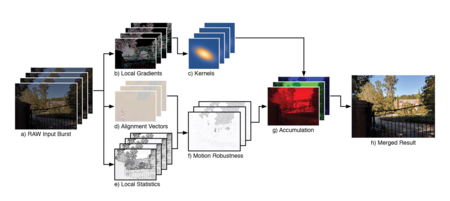 El algoritmo de Google, resumido.
El algoritmo de Google, resumido.
El proceso toma apenas 100 milisegundos por cada 12 fotos en RAW. Cuando se tienen las imágenes brutas, el algoritmo establece un fotograma base (recuerda que cada foto tiene un ángulo ligeramente distinto) y alinea y combina el resto de fotos con dicho fotograma base. Eso, usando solapamiento de señales (aliasing), se emplea para reconstruir una señal de mayor resolución.
A continuación, el algoritmo detecta los gradientes de la foto, es decir, las esquinas, bordes y texturas. En función de la escena, el algoritmo decide cuánto hay que mejorar la resolución de la señal y cuánto contribuye cada foto de las obtenidas anteriormente en dicha mejora. Aquí entran en juego funciones de base radial isotrópica gaussiana, pero la idea básica es que el algoritmo detecta los cambios de señal para analizar dónde están los bordes de los objetos y mantener la integridad de la foto.
 Si no se aplicase el modelo, la foto saldría con imperfecciones, ya que estamos combinando varias fotos tomadas en movimiento.
Si no se aplicase el modelo, la foto saldría con imperfecciones, ya que estamos combinando varias fotos tomadas en movimiento.
Algo que cabe preguntarse es: ¿qué pasa si estamos en movimiento? Si echamos una foto desde el coche, al combinar las fotos los elementos aparecerán movidos, ¿no? En absoluto. Google usa un modelo de robustez de movimiento local, que crea una serie de capas con los elementos movidos y los elimina. De esa forma, las aberraciones se borran y la foto queda congelada.
Juntando todas estas técnicas, Google consigue que podamos hacer zoom sin perder demasiada calidad, incluso con una sola lente y sin teleobjetivo dedicado. También es la base del modo nocturno, que ya hemos puesto a prueba y ha demostrado comportarse más que decentemente.
Más información | Google



Ver 2 comentarios